您好,欢迎光临某某户外篷房有限公司!
语言选择:


优化算法在机器学习,运筹,博弈论等领域是必不可少的算法。尤其是机器学习,模型往往并不复杂,复杂麻烦的往往是优化算法。python里面的scipy.optimize提供了丰富的优化算法。笔者在学习这一部分内容时,少有系统介绍这个包的中文文章。某虽不才,愿奋力一试。
对于大部分应用者而言,优化算法能用效果理想即可,至于里面的弯弯道道,各种证明想想就头疼,于实际应用亦无甚效果。故而,以程序应用为主,原理能不加则不加,不喜勿碰。
如若英文水平可以,则点链接看官方文档即可,无需看我废言。本文的主要逻辑也是继承于此文档。
https://docs.scipy.org/doc/scipy-1.5.1/reference/tutorial/optimize.html任何算法需要有个应用的对象,而优化领域最喜欢的小白鼠便是Rosenbrock函数,定义如下:
当其为二元函数时,图像如下:
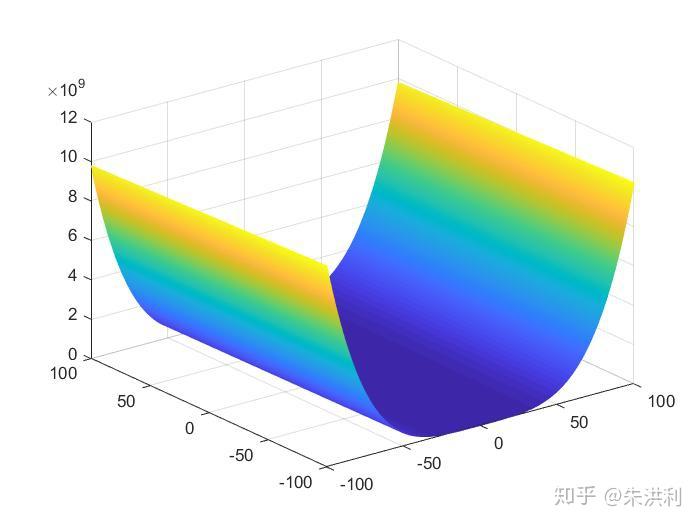
这个函数的最小值就是0,此时 。下面我们将用此函数作为优化的对象,看看scipy.optimize里的优化方法能否将此函数优化至0,且
。
所谓无约束就是没有约束呗,向量x的值随便取,只要能让被优化的函数最小就可以了。
下面就以theNelder-Meadsimplex algorithm(单纯性算法)为例,来看一下调用优化的代码该怎么写。
import numpy as np
from scipy.optimize import minimize
#把要用到的包import上
def rosen(x):
#定义Rosenbrock函数
return sum(100.0*(x[1:]-x[:-1]**2.0)**2.0 + (1-x[:-1])**2.0)
x0 = np.array([1.3, 0.7, 0.8, 1.9, 1.2])
#x0是我们给的迭代初值
res = minimize(rosen, x0, method='nelder-mead',
options={'xatol': 1e-8, 'disp': True})
#这就是我们调用minimize的方法,rosen是要被优化的函数,x0是给定的初值,method是采用的方法
print(res.x)Rosenbrock函数写的这是什么玩意,应该是看到这个定义的第一反应。其实这个也很好理解,我们上面那个式子是给人看的,而代码里面写的是让电脑计算的,输进去一个x就要出来一个对应的Rosenbrock函数值。大家对着式子仔细对照一下,x在式子中是一个向量,而在代码里面可以当做一个list看待,品一品应该会很快看明白。
运行一下:
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 18
Function evaluations: 1084
[1. 1. 1. 1. 1.]用不同的方法可以在method里面改。比如改成method='powell',此处的优化算法就改成了鲍威尔法。
但是呢,有些算法,不是仅仅把函数写进去就可以了,还需要梯度,海森矩阵等信息,看看这些优化算法应该如何实现。首先是BFGS算法,这个算法只需要梯度函数即可。
在应用此算法之前,我们首先应该计算Rosenbrock函数的梯度和海森矩阵。梯度就是对每个变量求偏导所组成的一个向量。(这部分不太懂的可以看看高数),我们求得
但是首尾稍微特殊一些,
将梯度命名为der函数,代码像下面这样写,品一品:
def rosen_der(x):
xm = x[1:-1]
xm_m1 = x[:-2]
xm_p1 = x[2:]
der = np.zeros_like(x)
der[1:-1] = 200*(xm-xm_m1**2) - 400*(xm_p1 - xm**2)*xm - 2*(1-xm)
der[0] = -400*x[0]*(x[1]-x[0]**2) - 2*(1-x[0])
der[-1] = 200*(x[-1]-x[-2]**2)
return der而后就可以应BFGS算法了。
res=minimize(rosen, x0, method='BFGS', jac=rosen_der,
options={'disp': True})
print(res.x)运行一下:
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 25
Function evaluations: 30
Gradient evaluations: 30
[1.00000004 1.0000001 1.00000021 1.00000044 1.00000092]
计算这个梯度怪麻烦的,能不能把它省掉,来试一下:
res=minimize(rosen, x0, method='BFGS',
options={'disp': True})
print(res.x)运行:
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 25
Function evaluations: 210
Gradient evaluations: 30
[0.99999925 0.99999852 0.99999706 0.99999416 0.99998833]也是可以的,不过效果显然不如加上梯度的,所以能加上最好加上,一分耕耘一分收获。
此外Newton-Conjugate-Gradient algorithm(牛顿共轭梯度算法)不仅需要计算梯度,还需要海森矩阵。为此我们在调用这种优化方法时只需再把海森矩阵的函数加上就可以了。海森矩阵的具体求法在此不加赘述,如果不懂百度一下就明白了了。
Rosenbrock的海森矩阵的程序表达为:
def rosen_hess(x):
x = np.asarray(x)
H = np.diag(-400*x[:-1],1) - np.diag(400*x[:-1],-1)
diagonal = np.zeros_like(x)
diagonal[0] = 1200*x[0]**2-400*x[1]+2
diagonal[-1] = 200
diagonal[1:-1] = 202 + 1200*x[1:-1]**2 - 400*x[2:]
H = H + np.diag(diagonal)
return H在调用牛顿共轭梯度时,代码之中只需加上海森矩阵就行了,如下:
res=minimize(rosen, x0, method='Newton-CG',
jac=rosen_der, hess=rosen_hess,
options={'xtol': 1e-8, 'disp': True})
print(rex.x)运行一下:
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 24
Function evaluations: 33
Gradient evaluations: 56
Hessian evaluations: 24
array([1. , 1. , 1. , 0.99999999, 0.99999999])
?不加海森矩阵行不行,行。加上更好。
不加海森矩阵,不加梯度行不行,不行。
有时候呢,我们会觉得海森矩阵太麻烦了,是一个矩阵,为此我们可以用一个向量代替,这个向量呢就是海森矩阵乘以任何一个向量。大概意思就是,比如我的海森矩阵是[1 2; 3 4]是一个2*2的矩阵,我们可以用[1 2; 3 4]*[x,y]代替也就是[x+2y 3x+4y],这样我们就不用输入一个矩阵了,输入后面的向量[x+2y 3x+4y]就ok了。
具体实现呢就是:
def rosen_hess_p(x, p):
x = np.asarray(x)
Hp = np.zeros_like(x)
Hp[0] = (1200*x[0]**2 - 400*x[1] + 2)*p[0] - 400*x[0]*p[1]
Hp[1:-1] = -400*x[:-2]*p[:-2]+(202+1200*x[1:-1]**2-400*x[2:])*p[1:-1] \\
-400*x[1:-1]*p[2:]
Hp[-1] = -400*x[-2]*p[-2] + 200*p[-1]
return Hp
res = minimize(rosen, x0, method='Newton-CG',
jac=rosen_der, hessp=rosen_hess_p,
options={'xtol': 1e-8, 'disp': True})
print(res.x)运行一下:
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 24
Function evaluations: 33
Gradient evaluations: 56
Hessian evaluations: 66
array([1. , 1. , 1. , 0.99999999, 0.99999999])其他的Trust-Region Newton-Conjugate-Gradient Algorithm ,Trust-Region Truncated Generalized Lanczos / Conjugate Gradient Algorithm,Trust-Region Nearly Exact Algorithm,只需要将method=分别改为method='trust-ncg', method='trust-ncg',method='trust-krylov'即可。
下面介绍有约束优化问题的调用方法。
更新中。。。。。。
Copyright © 2002-2022 奇亿-奇亿注册篷房销售站 Powered by EyouCms 地址:广东省广州市番禺经济开发区 备案号:ICP备9527188号 网站地图








